Estimating the causal impact of recommendation systems from observational data
Abstract
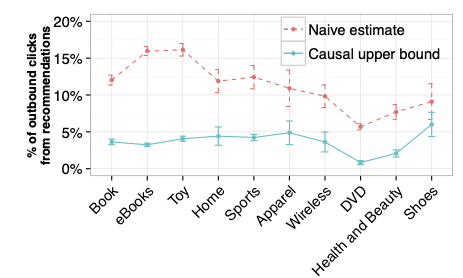
Recommendation systems are an increasingly prominent part of the web, accounting for up to a third of all traffic on several of the world’s most popular sites. Nevertheless, little is known about how much activity such systems actually cause over and above activity that would have occurred via other means (e.g., search) if recommendations were absent. Although the ideal way to estimate the causal impact of recommendations is via randomized experiments, such experiments are costly and may inconvenience users. In this paper, therefore, we present a method for estimating causal effects from purely observational data. Specifically, we show that causal identification through an instrumental variable is possible when a product experiences an instantaneous shock in direct traffic and the products recommended next to it do not. We then apply our method to browsing logs containing anonymized activity for 2.1 million users on Amazon.com over a 9 month period and analyze over 4,000 unique products that experience such shocks. We find that although recommendation click-throughs do account for a large fraction of traffic among these products, at least 75% of this activity would likely occur in the absence of recommendations. We conclude with a discussion about the assumptions under which the method is appropriate and caveats around extrapolating results to other products, sites, or settings.