ChatBench: from static benchmarks to human-AI evaluation
Abstract
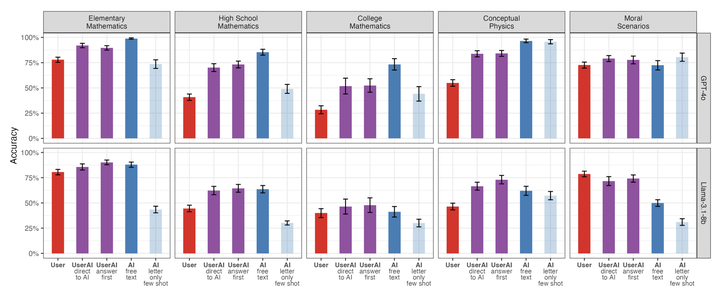
With the rapid adoption of LLM-based chatbots, there is a pressing need to evaluate what humans and LLMs can achieve together. However, standard benchmarks, such as MMLU, measure LLM capabilities in isolation (i.e., "AI-alone"). Here, we design and conduct a user study to convert MMLU questions into user-AI conversations, by seeding the user with the question and having them carry out a conversation with the LLM to answer their question. We release ChatBench, a new dataset with AI-alone, user-alone, and user-AI data for 396 questions and two LLMs, including 144K answers and 7,336 user-AI conversations. We find that AI-alone accuracy fails to predict user-AI accuracy, with significant differences across multiple subjects (math, physics, and moral reasoning), and we analyze the user-AI conversations to provide insight into how they diverge from AI-alone benchmarks. Finally, we show that fine-tuning a user simulator on a subset of improves its ability to estimate user-AI accuracies, increasing correlation on held-out questions by more than 20 points, creating possibilities for scaling interactive evaluation.