Sharding Social Networks
Abstract
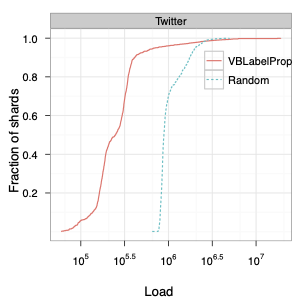
Online social networking platforms regularly support hundreds of millions of users, who in aggregate generate substantially more data than can be stored on any single physical server. As such, user data are distributed, or sharded, across many machines. A key requirement in this setting is rapid retrieval not only of a given user’s information, but also of all data associated with his or her social contacts, suggesting that one should consider the topology of the social network in selecting a sharding policy. In this paper we formalize the problem of efficiently sharding large social network databases, and evaluate several sharding strategies, both analytically and empirically. We find that random sharding—the de facto standard—results in provably poor performance even when frequently accessed nodes are replicated to many shards. By contrast, we demonstrate that one can substantially reduce querying costs by identifying and assigning tightly knit communities to shards. In particular, our theoretical analysis motivates a novel, scalable sharding algorithm that outperforms both random and location-based sharding schemes.