Effects of LLM-based Search on Decision Making: Speed, Accuracy, and Overreliance
Abstract
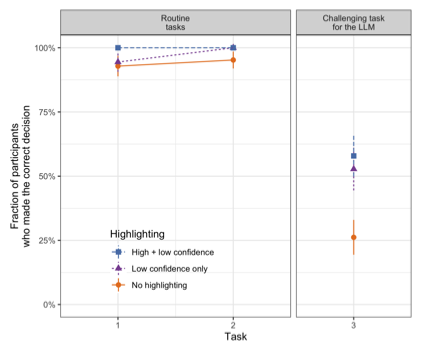
Recent advances in large language models (LLMs) are transforming online applications, including search tools that accommodate complex natural language queries and provide direct responses. There are, however, concerns about the veracity of LLM-generated content due to potential for LLMs to "hallucinate". In two online experiments, we examined how LLM-based search affects behavior compared to traditional search and explored ways to reduce overreliance on incorrect LLM-based output. Participants assigned to LLM-based search completed tasks more quickly, with fewer but more complex queries, and reported a more satisfying experience. While decision accuracy was comparable when the LLM was correct, users overrelied on incorrect information when the model erred. In a second experiment, a color-coded highlighting system helped users detect errors, improving decision accuracy without affecting other outcomes. These findings suggest that LLM-based search tools have promise as decision aids but also highlight the importance of effectively communicating uncertainty to mitigate overreliance.