Pre-registration for Predictive Modeling
Abstract
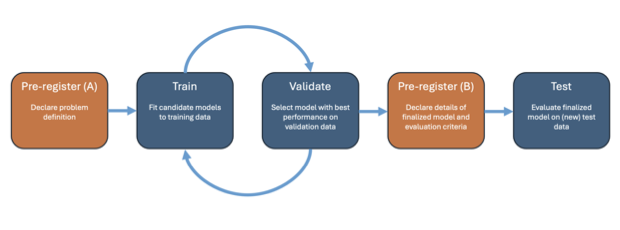
Amid rising concerns of reproducibility and generalizability in predictive modeling, we explore the possibility and potential benefits of introducing pre-registration to the field. Despite notable advancements in predictive modeling, spanning core machine learning tasks to various scientific applications, challenges such as overlooked contextual factors, data-dependent decision-making, and unintentional re-use of test data have raised questions about the integrity of results. To address these issues, we propose adapting pre-registration practices from explanatory modeling to predictive modeling. We discuss current best practices in predictive modeling and their limitations, introduce a lightweight pre-registration template, and present a qualitative study with machine learning researchers to gain insight into the effectiveness of pre-registration in preventing biased estimates and promoting more reliable research outcomes. We conclude by exploring the scope of problems that pre-registration can address in predictive modeling and acknowledging its limitations within this context.